Data Collection Methods for Enterprise AI in 2026

Introduction: The Data Dilemma in the Age of Enterprise AI
Here is a hard truth for 2026. Your enterprise AI is only as good as the data you feed it.

But most organizations are stuck with messy, scattered data collection methods that hold everything back.
The numbers back this up. According to the 2026 CIO Priorities Report, IT leaders are shifting their focus toward data, AI, and customer-led innovation. Yet a survey from Foundry’s 2026 State of the CIO shows that budget pressures and talent shortages make this shift tough. As Barracuda CIO Siroui Mushegian told CIO.com, scaling AI enterprise-wide without losing control is the biggest challenge.
That is where this guide comes in. We will walk through modern data collection methods that work for AI in 2026. You will learn how to move past fragmented systems and vendor confusion toward strategies that are scalable, governed, and real-time.
Whether you are dealing with information overload or trying to understand how tools like Google Cloud Vision or SAP systems fit into your AI overview, this article will help you see the full picture.
Get Free Updates from The Deep View Newsletter for simple daily AI insights.
The Data Collection Challenge in Modern Enterprises
Before we jump into solutions, let’s be honest about the barriers most companies face in 2026. If you have tried to build a clear AI overview of your operations, you already know the struggle. Data comes at you from every direction, and it rarely plays nice together.
Think about all the places your data lives. Your factory floor has IoT sensors. Your sales team runs customer interactions through a CRM. Your supply chain still relies on a legacy SAP system. And your marketing team uses different tools for everything. That is a lot of moving parts.
A recent survey of 100 senior data leaders at large enterprises found that managing this flood of information is a top concern. The sheer volume makes it hard to separate useful signals from noise. When your data collection methods are scattered, you end up with an overwhelming mess instead of a clear picture.
Here is the real problem. All that data sits in separate silos. Your finance system uses one format. Your customer service tool uses another.

Your visual data processed by tools like Google Cloud Vision adds yet another layer. These systems rarely talk to each other.
This inconsistency breaks your AI training. If you try to get an AI overview of your business and the underlying data is messy, your results will be unreliable. As one CIO put it, scaling AI enterprise-wide without losing control is the biggest challenge for 2026. Your data collection methods must be consistent, or your AI models will learn the wrong patterns.
And then there is the compliance piece. Leaders must balance the need for rich, granular data with strict privacy rules. You also have to worry about generative AI risks like data leakage and biased outputs. According to the 2026 State of the CIO report, budget pressures and talent shortages make this balancing act even harder.
These challenges are real, but they point us toward the right path. You need smarter, unified data collection methods built for the AI era. To stay ahead of these fast-moving trends without getting overwhelmed, you need a trusted source.
Get Free Updates from The Deep View Newsletter for simple daily AI insights that cut through the noise.
Automated Data Pipelines: Streamlining Collection at Scale
So, manual data collection methods are broken. The volume is too high. The formats are too messy. How do you fix this?
The answer is automation. You need automated data pipelines that handle the heavy lifting for you. These systems take data from your CRM, your SAP system, your IoT sensors, and even your visual tools like Google Cloud Vision. They clean it, reformat it, and move it where it needs to go with minimal human effort.
This shift changes everything. Instead of spending hours manually moving spreadsheets or writing one-time scripts, your team focuses on higher value work.

Automated pipelines dramatically reduce manual errors in data ingestion and transformation. They give you a single, reliable source of truth for your AI overview.
Real-Time Collection at Scale
In 2026, waiting for batch updates is not fast enough. Your operations move in real time. Tools like Apache Kafka allow for near-real-time data collection across dozens of different sources. Cloud-native data factories make it easier to scale this up without managing complex server infrastructure.
A well-designed pipeline also handles integration. It breaks down the silos we talked about earlier. Your sales data automatically talks to your supply chain data. Your finance numbers update instantly when a customer places an order.
Observability and Data Lineage for AI
But here is the catch. You cannot just set up a pipeline and walk away. Your AI and ML models depend on trustworthy input. If your pipeline breaks or transforms data incorrectly, your models learn the wrong patterns.
That is where pipeline observability comes in. You need to monitor the health of your pipeline at every step. You also need data lineage tracking. This tells you exactly where a piece of data came from and how it was changed along the way. This is critical for compliance and for debugging your AI training.
Following the latest best practices helps you build these systems correctly. According to a recent guide on building modern data pipelines, setting clear goals and focusing on governance are top priorities for teams in 2026.
Building these automated pipelines is a big step. It takes your data collection methods from messy to manageable. But the technology changes fast.
To stay on top of the latest strategies without the noise, Subscribe Free to The Deep View Newsletter.
Real‑Time Data Streaming for AI Applications
Automated pipelines solve the volume problem. But what about speed? When your AI needs data within milliseconds, batch pipelines just don’t cut it anymore. That is where real-time data streaming comes in.
Think about it this way. Your old methods moved data from point A to point B in a few hours. That worked for last month’s sales report. It does not work for fraud detection or dynamic pricing. By the time the data arrives, the opportunity is gone.
Real-time streaming tools like Apache Kafka and Apache Flink change that completely. They process data as it happens. Every click, every sensor reading, every transaction flows straight into your AI models with almost no delay. According to a guide on building real-time data pipelines from Integrate.io, this low latency is critical for operational decisions that need instant responses.
Use Cases That Demand Speed
Let me give you some real examples from 2026.
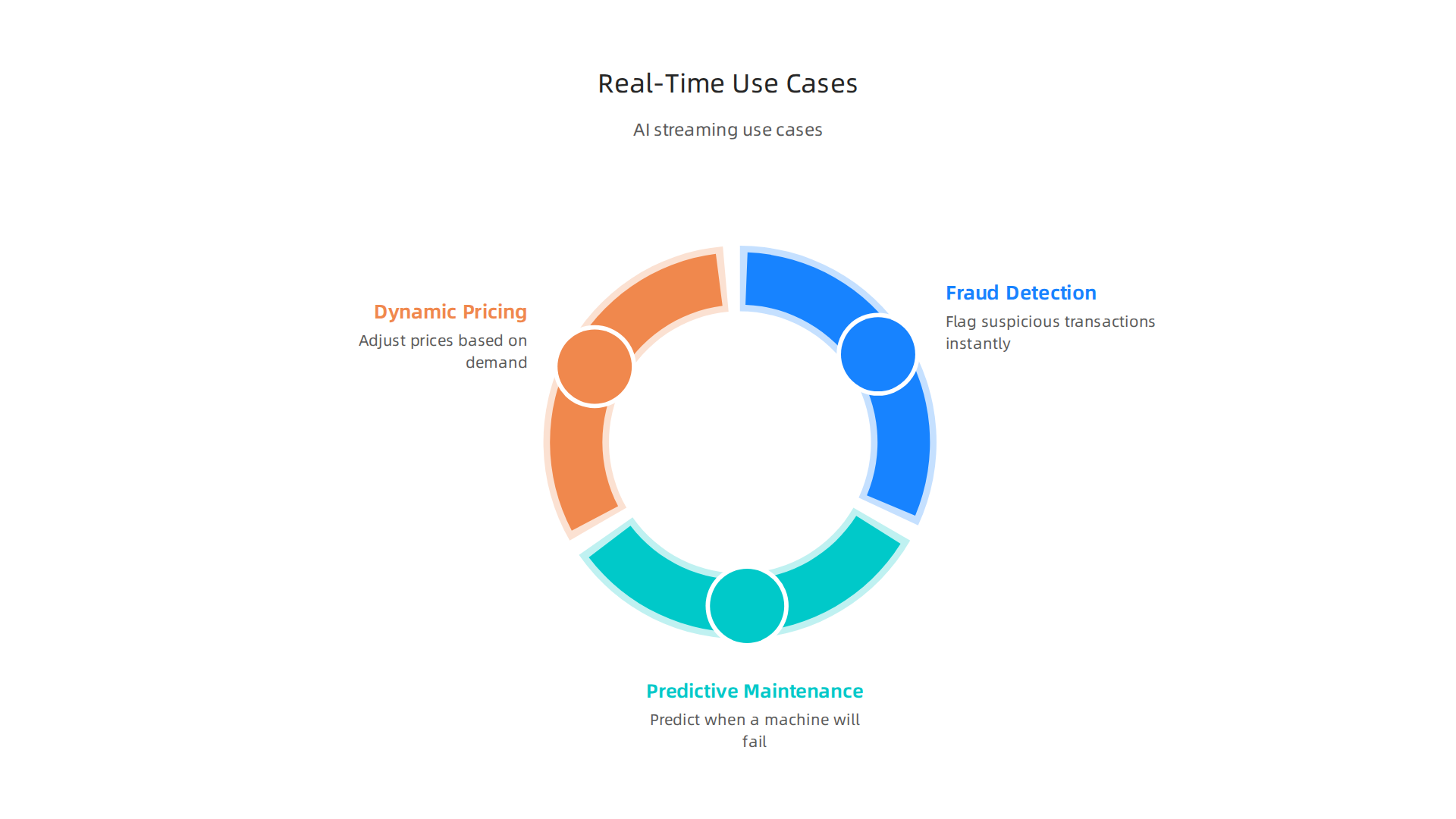
Fraud detection is a classic one. Banks use streaming to flag suspicious transactions before they complete. The AI model checks the transaction against historical patterns and known fraud signals in less than a second. If something looks wrong, the system stops it right there.
Predictive maintenance works the same way. Your factory equipment sends sensor data continuously. A streaming pipeline feeds that data into an ML model that predicts when a machine will fail. You get a warning before the breakdown happens, so you can schedule repairs during downtime.
Dynamic pricing is another big one. Airlines and ecommerce sites adjust prices based on current demand, competitor pricing, and inventory levels. Real-time data from your SAP system and web traffic feeds the pricing model instantly.
These applications all rely on modern data collection methods that prioritize speed. As the guide to AI data pipelines from Skyvia explains, a well-designed streaming architecture is essential for these high-frequency use cases.
The Hard Parts of Stream Processing
But here is the honest truth. Real-time streaming is not easy. You face real challenges that batch processing does not.
Stream processing complexity is the biggest one. Your system has to handle out-of-order data, duplicate events, and exactly-once processing guarantees. State management is another headache. Your streaming application needs to remember past events to make decisions, but keeping that state correct at scale is hard.
According to best practices from the Striim guide on data pipelines, you need strong orchestration and monitoring to keep your stream processing healthy. You also need to think about data lineage even in real time. Knowing where each event came from helps you debug issues fast.
The enterprise data streaming approach from Confluent suggests that companies that invest in these architectures see huge benefits. But you have to go in with your eyes open about the complexity.
The Payoff Is Worth It
Despite the difficulty, real-time streaming is the key to making your AI applications truly responsive. It turns your data collection methods from a slow process into a competitive advantage. Your models get fresh data instantly. Your teams get insights as they happen.
And the best part? The technology keeps getting better. Tools keep maturing. Cloud platforms make stream processing more accessible every year.
To stay ahead of these fast-moving trends, you need a clear signal in the noise. The Deep View Newsletter delivers daily insights on enterprise AI and data strategies without the hype.
Get Free Updates and never miss a critical update.
Synthetic Data: A Strategic Approach to Filling Data Gaps
You just saw how real-time streaming feeds your AI models with live data. But here is a hard truth that many teams face. What do you do when you do not have enough real data to train those models in the first place?
Maybe your data is too scarce. Maybe privacy rules stop you from using it. Or maybe the data you have is so sensitive that sharing it with your team creates a compliance nightmare.
That is where synthetic data generation changes everything.
What Is Synthetic Data, Really?
Synthetic data is artificially created information that mimics real-world data. It looks like your actual customer transactions or sensor readings. But it is completely generated by algorithms. No real person or event is involved.
This approach gives you two huge advantages. First, you can create as much data as you need. Want a million training examples for your computer vision model? Just generate them. Second, you avoid all the privacy and compliance risks that come with real customer data.
According to best practices in AI-powered data governance, this is becoming a standard strategy for teams that need to balance model performance with regulatory requirements. The key is doing it right.
How Privacy-Preserving Techniques Work
Two main approaches dominate in 2026.

Generative adversarial networks (GANs) are the most common. You train two neural networks against each other. One creates fake data. The other tries to spot the fakes. Over time, the generator gets so good that its output is nearly indistinguishable from real data.
Differential privacy adds another layer. It injects carefully controlled noise into the training process. This ensures that even if someone looks at the synthetic data, they cannot reverse-engineer information about any real person.
These techniques help you stay compliant with frameworks like the NIST AI Risk Management Framework. Using synthetic data reduces the risk of exposing personally identifiable information while still giving your models the volume they need.
Validation Is Not Optional
Here is where teams often slip up. They generate synthetic data and feed it straight into their models without checking if it is any good.
That is a mistake.
You need a validation framework to make sure your synthetic data maintains realistic statistical properties. The correlations between variables should match real data. The edge cases should look similar. The distribution of values should feel natural.
According to a comprehensive guide on data governance frameworks from Quinnox, validation is critical for maintaining data quality across your entire pipeline. Without it, you risk training models that work on synthetic data but fail in the real world.
Making Synthetic Data Part of Your Strategy
The smartest teams in 2026 do not see synthetic data as a replacement for real data. They see it as a supplement. Use real data where you can. Use synthetic data where you must.
This hybrid approach lets you train better models, move faster, and sleep easier knowing your compliance is covered.
To get all the latest insights on AI governance and data strategy delivered directly to your inbox, subscribe to The Deep View Newsletter.
Subscribe Free and stay ahead of the curve.
Data Quality and Governance: The Foundation for Trustworthy AI
Here is a hard truth that keeps many AI leaders up at night. You can have the most advanced model architecture in the world. You can feed it synthetic data and real-time streams. But if your underlying data collection methods are sloppy, your AI will still produce bad results.
That is not a guess. It is proven fact. Poor data quality and weak governance are the number one reasons enterprise AI projects fail. Biased inputs produce biased outputs. Inaccurate data leads to bad decisions. And when regulators come knocking, lack of proper governance gets you into serious trouble.
Why Data Quality Matters More Than Ever
Think about what happens inside an AI model. The algorithm learns patterns from whatever you feed it. If your data is incomplete, duplicated, or full of errors, the model learns those flaws. The result is an AI that looks good in testing but fails in the real world.
This is where your data collection methods come under scrutiny. According to best practices for AI-powered data governance, implementing strong quality checks at the point of collection is the first line of defense.

You cannot fix bad data later. You have to catch it early.
Data cataloging and lineage tracking are no longer optional. You need to know exactly where every piece of data came from, how it was transformed, and who touched it. This transparency is what makes regulatory compliance possible. Frameworks like the NIST AI Risk Management Framework require this level of visibility to manage AI risk properly.
Automated Quality Monitoring Is Now Standard
In 2026, manual data quality checks are not enough. The scale is too large and the pace is too fast. Enterprise teams are adopting automated data quality monitoring tools that run continuously across their pipelines.
These tools scan for anomalies, flag inconsistencies, and score data quality in real time. Some of the top AI-powered data governance tools in the market now include automated metadata management and lineage tracking as core features. This is what makes a governance framework actually work in practice.
According to a comprehensive guide on data governance for AI, the most successful teams treat governance as an ongoing process, not a one-time project. They embed quality checks into every stage of the data lifecycle.
What You Can Do Right Now
Start with a simple audit. Map out every data source your AI models use. Check for completeness, accuracy, and consistency. Assign quality scores. Then build automated checks that catch problems before they reach your models.
This is the foundation that makes everything else possible. Without it, your AI is built on sand.
To get more practical guidance on enterprise data strategy and AI governance, join the thousands of leaders who read The Deep View Newsletter every day.
Subscribe Free and get actionable insights delivered to your inbox.
Choosing the Right Data Infrastructure for AI Integration
Once you have clean data and solid governance, the next big question hits you. Where do you actually store and process all this data for your AI?

Your answer to that question shapes everything from cost to speed to long term flexibility.
Here is the reality. The infrastructure you choose directly impacts your data collection methods. If you pick a cloud only setup, your data has to travel over the internet. That adds latency. If you go fully on premises, you control everything but face big hardware costs and scaling limits. According to the 2026 Enterprise Cloud Index from Nutanix, IT leaders are struggling to balance all these trade offs as AI workloads explode. Hybrid architectures are becoming the default for many teams because they offer the best of both worlds.
Cloud, On Prem, or Hybrid: What Matters for AI
Think about a computer vision project using Google Cloud Vision. You want to process images in real time. If your data sits in an SAP system on premises, sending it to the cloud for every API call adds delay. A hybrid setup lets you run inference near the data while using the cloud for training and burst capacity.
This is not just about latency. It is about cost. Moving large volumes of data around costs money. The right architecture reduces how much you move. The HyperFRAME Lens Research shows that leading enterprises are rethinking their entire AI stack to match data gravity with compute location.
Data Lakehouses: The New Standard
Old school data warehouses were not built for AI. Data lakes were messy. The solution in 2026 is the data lakehouse. It unifies storage and analytics in one place. According to the 2026 State of Modern Data Architecture: Benchmark Report, lakehouse architectures are now the most common choice for AI ready setups. They let you store raw data, run analytics, and train models without moving data between systems.
Watch Out for Vendor Lock In
Here is the trap. Many platforms look great today but make it hard to leave later. Proprietary formats and APIs keep you tied to one vendor. That hurts your ability to switch as your needs change. Interoperability matters. Open table formats like Apache Iceberg help avoid lock in. Platforms like Acceldata now offer autonomous data management that works across cloud, on premises, and hybrid environments, giving you flexibility.
Making the wrong infrastructure choice now creates big problems later. That is why staying informed on these trends is so important. Join the thousands of leaders who get clear daily updates.
Subscribe Free to The Deep View Newsletter and keep your AI strategy on track.
Building the Data and AI Talent Pipeline
Here is a hard truth. You can have the best infrastructure in the world. You can have clean data and solid governance. But without the right people, none of it matters.
The shortage of data engineers, ML engineers, and data architects is real. It directly hurts your data collection methods because you do not have enough skilled people to design and maintain the pipelines. According to the HyperFRAME Lens Research on the State of the Enterprise AI Stack, companies across every industry are struggling to find talent that understands both data systems and AI workloads. The gap is not small. It is one of the top reasons AI projects stall or fail.
Upskilling Your Current Team
The smartest companies in 2026 are not just trying to hire. They are growing their own talent.

Taking a great database administrator and training them on ML pipelines often works better than hunting for a unicorn candidate who does everything. University partnerships are another common strategy. Internships and co-op programs build a direct pipeline from classrooms to your data teams.
This approach does more than fill seats. It builds institutional knowledge. People who already understand your SAP system and your Google Cloud Vision workflows can learn AI skills faster than outsiders.
Automation to the Rescue
Here is the good news. You do not need a specialist for every routine task anymore. Automation and low-code platforms are changing the game. Tools are getting smarter. Platforms like Acceldata now offer autonomous data management that handles many routine data collection methods without a human writing every line of code.
This matters more than you think. When your senior data architects are freed from repetitive work, they can focus on the hard problems. The problems that actually move the needle on your generative AI risks and compliance concerns. The 2026 State of Modern Data Architecture: Benchmark Report shows that teams using automation for routine tasks see faster AI deployment and fewer errors.
The talent shortage is not going away overnight. But with upskilling and smart automation, you can build a team that works.
Get clear daily AI insights delivered to your inbox.
Navigating Security, Privacy, and Vendor Risk
Your data collection methods might be putting your company in danger. Not because the data is wrong, but because the rules keep changing. And your vendors are making it harder.
The Privacy Landscape in 2026
Here is the reality. Privacy laws are getting tighter every year. If you operate in Europe, you already know about GDPR. But now the EU AI Act has joined the party. This law governs how AI systems are built and used, which directly affects how you collect and process data EU AI Act vs. GDPR. In the United States, laws like the CCPA are also evolving. The 2026 Privacy Law Updates report shows enforcement action is ramping up across the Americas, EMEA, and APAC 2026 Privacy Law Updates.
What does this mean for you? Your data collection methods must be designed with compliance in mind from day one. You cannot just collect everything and ask for forgiveness later. The fines are too big.
The Vendor Complexity Trap
Most enterprises do not use one tool for data collection. They use many. You might have a SAP system for enterprise data, a Google Cloud Vision setup for image processing, and a dozen other platforms. Each one collects data differently. Each one has its own security settings.
This creates gaps. A security team might lock down one tool but forget another. Sensitive customer data can leak through a generative AI risks scenario where a model accidentally exposes training data. The more vendors you have, the more surfaces an attacker can target.
Risk Mitigation That Actually Works
The best defense is a simple framework. Start with strong data encryption for everything at rest and in transit. Use strict access controls so only the right people see sensitive data. And run regular vendor assessments. Ask your suppliers what they do with your data. Ask about their compliance certifications.
This should be part of your ai overview strategy. A solid governance plan saves you from expensive surprises.
Get clear daily AI insights delivered to your inbox.
Summary
This article explains how modern data collection methods power enterprise AI in 2026 and what teams must change to get reliable, compliant results. It reviews the core problems—fragmented sources, inconsistent formats, and rising privacy rules—and shows practical solutions: automated pipelines, real‑time streaming, synthetic data generation, and continuous data quality and lineage tracking. The piece also covers infrastructure tradeoffs (cloud, on‑prem, hybrid and lakehouse architectures), how to build and upskill a data + AI workforce, and how to manage vendor, security, and compliance risk. Readers will learn which technologies and governance practices to prioritize, when to use streaming versus batch or synthetic data, and how to validate and monitor inputs so AI models produce trustworthy outcomes. The guidance is focused on scalable, governed methods that reduce manual effort and support enterprise AI at speed.